简单来说,它的核心定位是:ElevenLabs 的本地、开源、免费替代品。
它可以让你仅凭几秒钟的音频样本,就在你自己的电脑上完美复刻(克隆)任何声音,并进行高质量的文本转语音(TTS)合成,而整个过程完全离线运行,不需要任何云端订阅,也保护了数据隐私。
你可以从以下几个核心亮点来了解这个项目:
1. 极其强大的多引擎底层
Voicebox 并不是一个单一的模型,而是一个声音底座聚合平台。它内置并集成了 7 个各具特色的 TTS 算子引擎,你可以根据需求随时切换:
Qwen3-TTS (0.6B / 1.7B)、Chatterbox Turbo / Multilingual、HumeAI TADA (1B / 3B)、Kokoro / LuxTTS
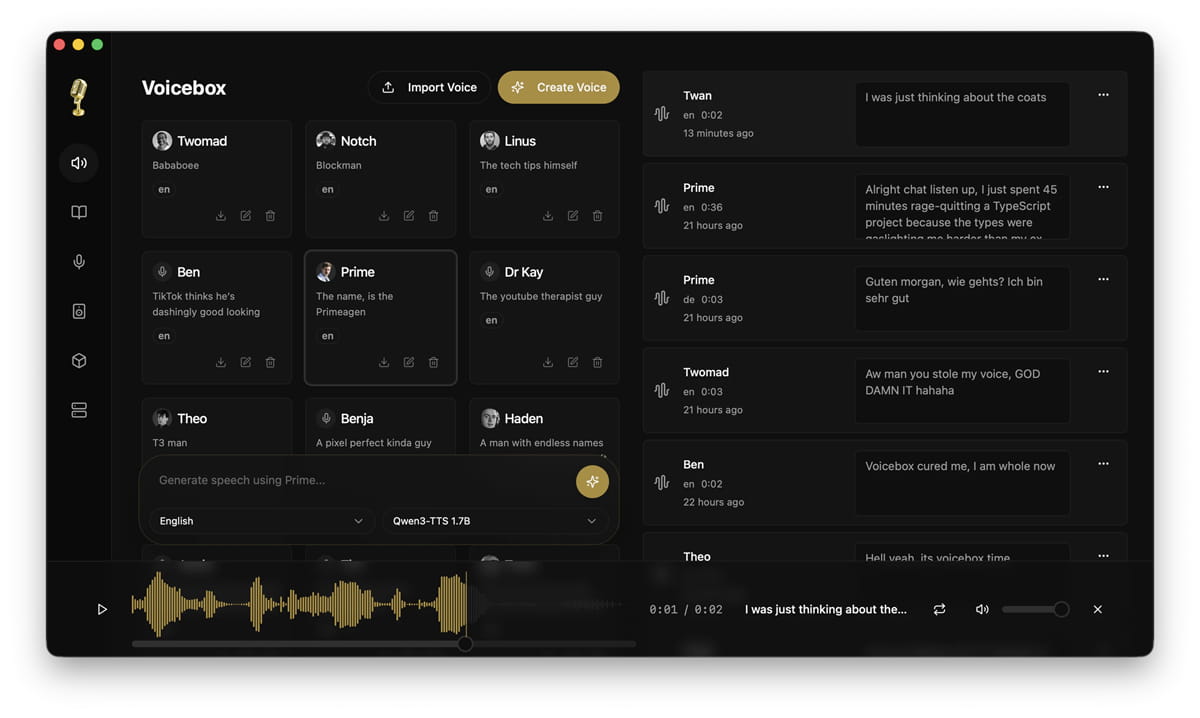
2. 音频工作站(DAW)级别的界面与工作流
与其他单调的“输入文字、点击生成”的 AI 语音工具不同,Voicebox 是围绕“工作室(Studio)”概念设计的:
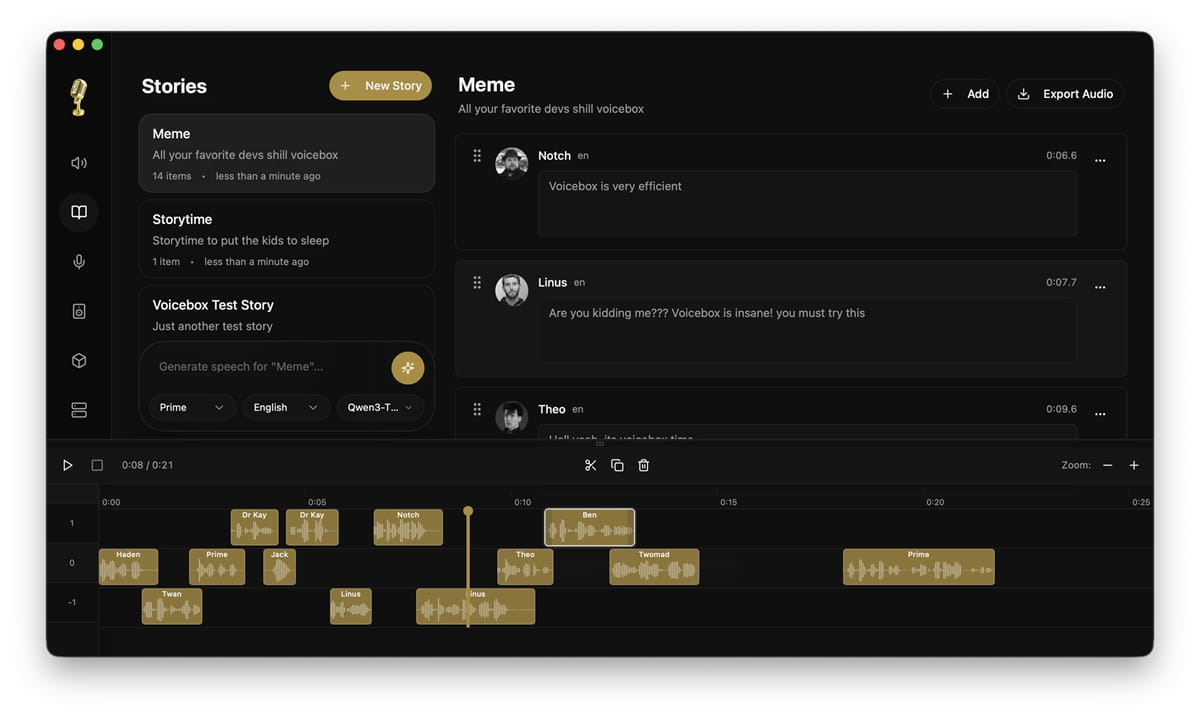
Stories 故事编辑器(多轨时间轴):它自带一个类似剪辑软件的多音轨时间轴(Timeline)。你可以像在 DAW(数字音频工作站)里一样,把不同的克隆角色拖到不同轨道上排版,轻松拼凑出一段双人对话、多人播客或者有声书剧本。
异步生成队列:文字太长时它会自动在句子边界处切片(支持高达 50,000 字),每句话独立异步生成并支持淡入淡出(Crossfade)无缝拼接。你可以一边打字提交,后台一边批量渲染,完全不卡顿。
Spotify 级别的音频后处理:内置了基于 Pedalboard 库的 8 种音频效果器。生成完声音后,你可以直接在软件里调混响(Reverb)、延迟(Delay)、变调(Pitch Shift)或者高低通滤波,打造出类似“收音机”、“机器人”或“空旷房间”的音效。
3. 从微型工具到全局生态(Version 0.5+)
在最新的重大更新中,Voicebox 已经不仅仅是一个语音合成器,它变成了一个全局的“声音输入/输出平台”:
全局全局听写(System-wide Dictation):利用内置的 Whisper 模型,你可以通过全局快捷键呼出一个浮动条,直接在电脑的任何软件里通过语音输入。最厉害的是,它自带一个本地的 Qwen 语言模型,会自动帮你抹除语气词(“嗯、啊”)、修正标点,甚至能按照你指定的 Profile 语气来润色你的听写文本。
开发者友好(API & MCP):它采用了 API-first 的设计架构。这意味着你不仅可以通过它精美的 GUI 界面用它,还能通过本地本地 REST API 或者 MCP (Model Context Protocol) 协议,把它直接对接到你的 AI 智能体(Agents)、自动化脚本或代码工作流中。
4. 极致的本地技术栈
在 Windows/Linux 上,它支持 NVIDIA、AMD、Intel 显卡的全套 PyTorch/ROCm/DirectML 加成,也支持纯 CPU 垫底运行。